GPU Monitoring is a Black Hole - Say Hello to Neurox
Background:
When I co-founded Mezmo (fka LogDNA, Series D observability startup), I learned firsthand how critical app-level observability is for DevOps, cutting through logging noise and finding the needle in the haystack is everything. At Mezmo, the key was providing teams with the necessary context to investigate, debug, and resolve issues quickly.
But stepping into the AI space, I immediately noticed a glaring blind spot: GPU monitoring. Despite skyrocketing GPU investments, teams had virtually no clear way to track usage, manage costs, or even identify idle resources across multi-cloud environments.
GPUs were becoming a budget black hole, and the best “solution” was cobbling together dashboards and graphs found online. So Lee and I said, screw it, let’s fix this :)
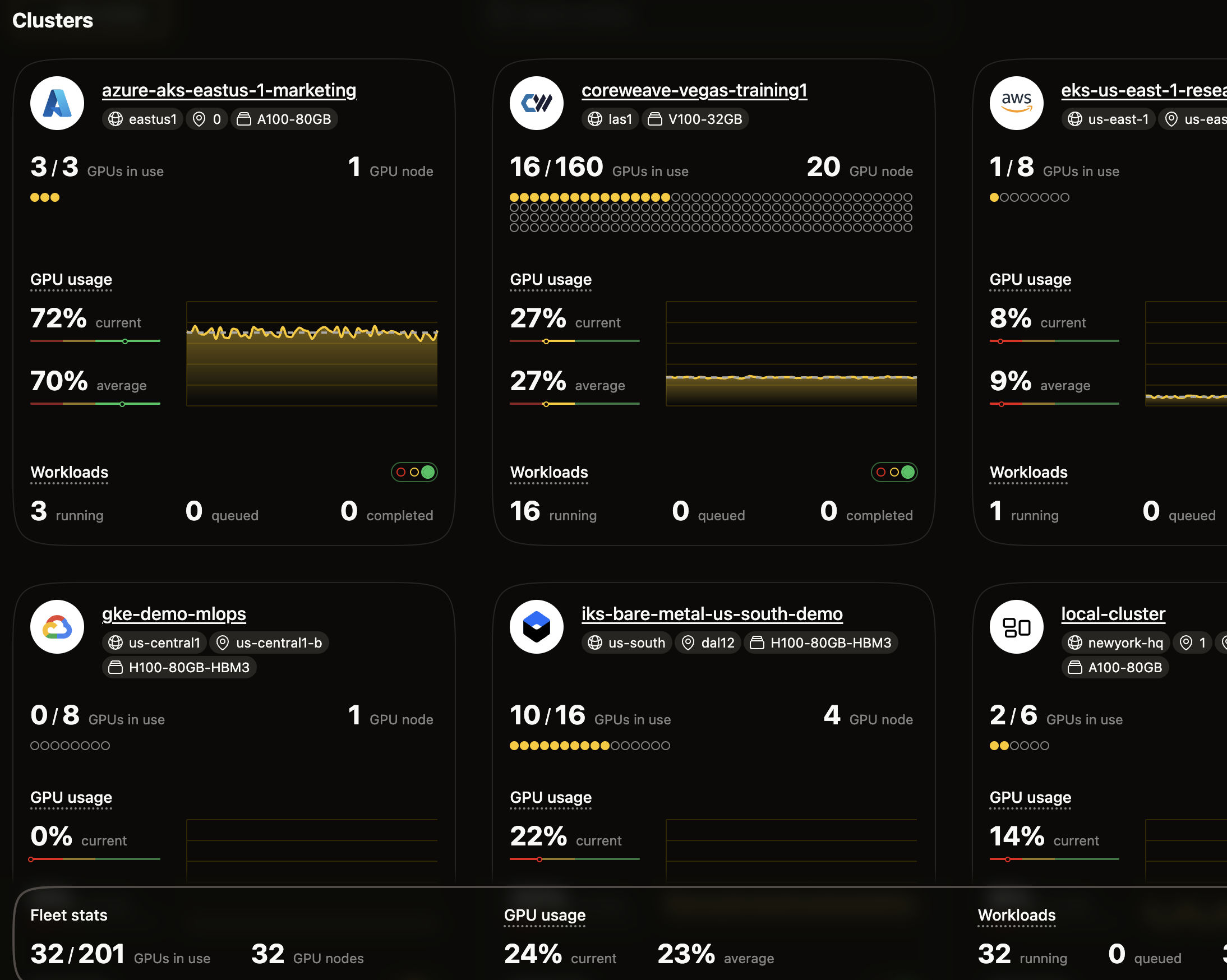
The Problem Today:
Most companies still can’t track GPU costs by team in real time, despite spending billions on infrastructure. Without clear cost accountability, more than half of their GPUs sit idle, draining budgets and slowing AI progress. FinOps teams lack the granularity they need for ROI, while MLOps teams scramble to keep clusters healthy.
We’re Just Getting Started:
We’re still in the early innings of AI’s game, and GPUs are the star players just getting warmed up. Here are three plays we’re seeing unfold:
Multi-cloud is the new standard - Multi-cloud is the new normal; it’s not just for enterprises anymore. Teams large and small run compute across clouds and on-prem. GPU monitoring must deliver a unified view across all environments.
Kubernetes is the unifying layer - Kubernetes has become the de facto standard for orchestrating AI workloads acting as the unifying layer between multi-cloud environments.
Metrics alone won’t cut it —** **observability without FinOps is incomplete. To truly understand GPU usage and AI workloads, you need real-time insights that connect metrics, Kubernetes state, and FinOps.
Introducing Neurox:
Neurox is the first purpose-built GPU monitoring platform specifically for multi-cloud AI infrastructure. It gives teams real-time visibility into GPU usage, project-level costs, and workload health. No more guessing “who spent $500K on AI compute last month”.
With Neurox, teams can finally measure real returns on both value and investment. We’re the missing layer between GPU orchestration and cloud-native monitoring, especially where DevOps, FinOps, and now security teams are flying blind.
Give Neurox a spin. Explore, test, and let us know what we’re missing.
Excelsior!
Chris, Lee and Team